
Your ML Model Is Underperforming? Debug It Like an Interview-Ready Engineer.

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Your ML Model Is Underperforming? Debug It Like an Interview-Ready Engineer
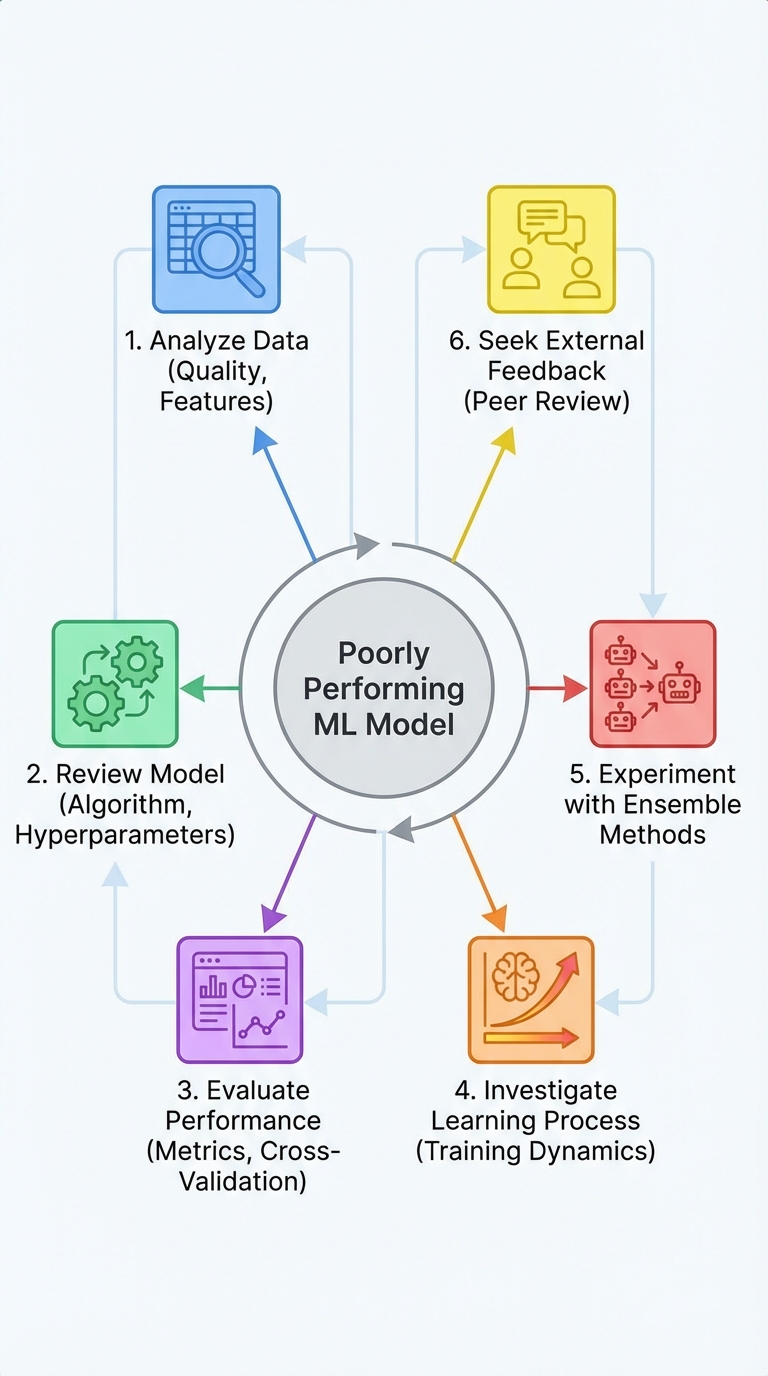
A weak ML model is rarely just "bad luck"—it's usually a process failure. Treat debugging like a disciplined engineering task: follow a repeatable checklist, gather evidence, and iterate. Below is a compact, interview-ready guide to track down why your model is underperforming and what to do about it.
1) Data — the most common culprit
- Validate basic assumptions: ensure no accidental label shifts, duplicate rows, or inconsistent units.
- Missing values: examine patterns (missing completely at random vs not). Impute thoughtfully (median, mode, or model-based) and log what you changed.
- Outliers: detect with IQR or robust z-scores. Decide whether to clip, transform, or remove.
- Distribution drift: compare train vs test (KS test, PSI, or train-a-classifier-to-separate approach). For time-series use rolling windows.
- Scaling: scale numeric features when required (SVMs, logistics, neural nets). Use pipelines so transformations are applied identically to train/val/test.
Quick checks:
- pd.DataFrame.describe(), value_counts(), histograms
- Visualize label balance and feature distributions
2) Features — signal vs noise
- Remove irrelevant or constant features.
- Check multicollinearity (correlation matrix, VIF). Collapse or remove redundant features.
- Feature importance: use model-based importances, permutation importance, or SHAP to spot noisy or harmful features.
- Feature engineering: create interaction terms, bucket continuous variables, or transform skewed features (log, Box–Cox).
Tip: Keep a simple baseline model (logistic/regression/tree) to quickly evaluate feature changes.
3) Model — underfit vs overfit
- Underfitting signs: train and validation scores both low. Solution: increase model capacity, add features, reduce regularization.
- Overfitting signs: high train score, low validation score. Solution: regularization, more data, dropout, early stopping, simpler model.
- Hyperparameter tuning: grid search / random search / Bayesian optimization (e.g., Optuna). Use nested CV or a held-out validation set to avoid leakage.
Example (scikit-learn): use Pipeline + GridSearchCV or RandomizedSearchCV to ensure transformations and tuning are combined reliably.
4) Evaluation — are you measuring the right thing?
- Choose the metric that matches business goals: accuracy, F1, AUC, precision@k, RMSE, MAE, etc.
- For imbalanced classes prefer F1, precision-recall AUC, or use class-weighting/sampling strategies.
- Use cross-validation (StratifiedKFold for classification, TimeSeriesSplit for temporal data) to estimate generalization.
- Beware of metric traps: AUC can be misleading if calibration matters; accuracy can hide class imbalance.
5) Training — inspect dynamics
- Plot learning curves (train vs validation loss/metric) to diagnose capacity/data issues.
- Watch for vanishing/exploding gradients in deep nets; use gradient clipping, better initialization, or normalization layers.
- Check batch size, optimization algorithm, learning rate schedule, and whether early stopping is being used effectively.
- Ensure reproducibility: set seeds, record package versions, log experiment metadata.
Tools: TensorBoard, MLflow, Weights & Biases, or custom logging to track experiments.
6) Improve — structured next steps
- Ensembling: bagging, boosting, stacking — often gives robust gains but increases complexity.
- More data: label more examples or augment data if possible. Synthetic data only with caution.
- Peer review: get another engineer to inspect code, data pipelines, and assumptions (data leakage is commonly caught this way).
- Small experiments: run one change at a time and track the impact in a reproducible way.
Quick interview-ready checklist
- Is my metric aligned with the business question?
- Is there data leakage between train and test?
- Do train and test distributions match? If not, why?
- Are features informative and non-redundant?
- Is the model underfitting or overfitting? What evidence supports that?
- Are my experiments reproducible and well-logged?
Short troubleshooting playbook (first 30–60 minutes)
- Run basic EDA: label balance, missing values, basic stats.
- Sanity-check the pipeline: ensure preprocessing is identical for train/val/test.
- Train a simple baseline model and compare.
- Plot learning curves and feature importances.
- If no obvious cause, run a small ablation: remove suspicious features or regularize more strongly.
Resources
- scikit-learn pipelines, GridSearchCV / RandomizedSearchCV
- Permutation importance & SHAP for explainability
- TensorBoard / MLflow / Weights & Biases for experiment tracking
Debugging is a process, not luck. Use data, evidence, and repeatable experiments to converge on a fix. Treat each training run as an experiment: document it, test one hypothesis at a time, and ask peers for review.
#MachineLearning #DataScience #MLOps #ModelDebugging #FeatureEngineering #HyperparameterTuning #InterviewPrep

