
Database Partitioning in System Design: Horizontal vs Vertical (Know This for Interviews)

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
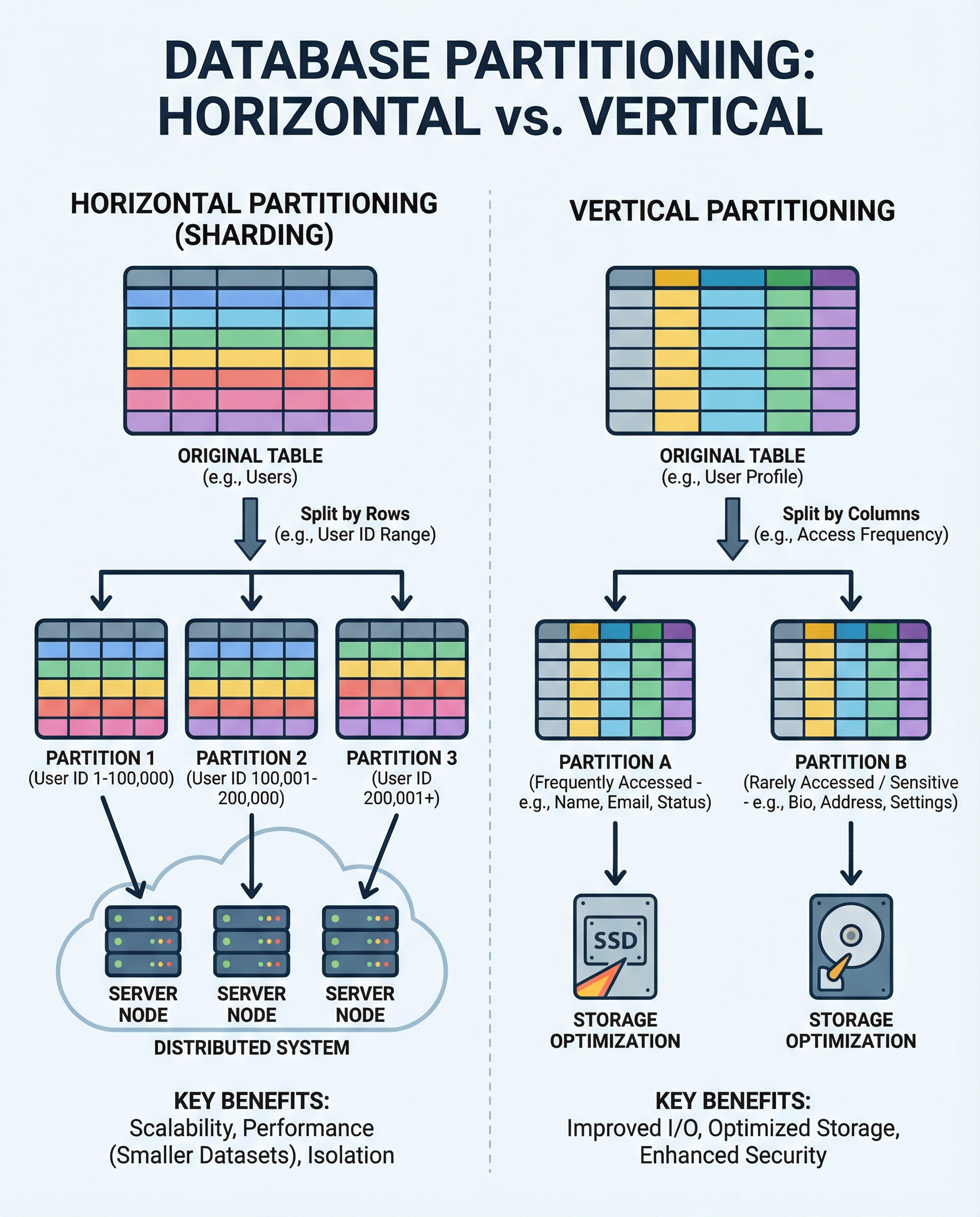
Database Partitioning in System Design: Horizontal vs Vertical
Partitioning splits a large database into smaller, more manageable pieces to improve performance, scalability, and maintainability. In interviews you’ll often be asked when to partition and which strategy to choose. The short, memorable rule: pick based on access patterns and growth.
Below is a concise guide to the two primary partitioning strategies, their trade-offs, common patterns, pitfalls, and what to say in an interview.
What is Horizontal Partitioning (Sharding)?
Horizontal partitioning, or sharding, splits a table’s rows across multiple database instances. Each shard holds a subset of rows determined by a shard key (e.g., user_id, account_id, or a time range).
Pros:
- Queries touch smaller datasets → lower latency for shard-local queries
- Better write/read throughput because load is distributed
- Fault isolation: one shard can fail without taking down all data
- Easier to scale out by adding shards
Cons:
- Cross-shard joins and transactions are harder or more expensive
- Hot shards (uneven key distribution) lead to imbalanced load
- Re-sharding (reshuffling data) can be operationally complex
- Increased infrastructure and operational complexity (routing, metadata)
Common shard strategies:
- Hash-based: evenly distributes keys (good default)
- Range-based: good for time-series and range queries
- Directory-based: explicit mapping for complex distributions
Example: Shard users by user_id hash, or shard time-series by month/year ranges.
What is Vertical Partitioning?
Vertical partitioning splits a table by columns. You separate frequently accessed (“hot”) columns from rarely used (“cold”) ones, or isolate sensitive fields into their own table.
Pros:
- Fewer bytes read per query → improved I/O and cache efficiency
- Better performance for narrow, common queries on wide tables
- Easier to apply different storage/backup policies (hot vs cold)
- Isolation of sensitive data (e.g., move PII to a hardened table)
Cons:
- Requires joins across vertical partitions for full-row reads
- More complex schema with additional foreign keys
- May need additional care for transactional consistency across partitions
Common vertical patterns:
- Hot/cold split: place frequently read columns in the main table; archive old columns elsewhere
- Functional split: profile data vs authentication data vs analytics columns
- Large binary data (images, blobs) moved to object storage or separate tables
Example: Move profile_photos and large JSON blobs to a separate table or blob store; keep core user fields (id, name, email) in the main table.
Decision Checklist (what to say in interviews)
- Identify access patterns: Are reads/writes focused on subsets of rows (good for sharding) or on a few columns of many rows (good for vertical)?
- Estimate growth: Is data volume or QPS expected to grow horizontally (more users) or vertically (wider schemas)?
- Consider transaction and join requirements: Do you need strong cross-row transactions or complex joins? If yes, sharding can complicate things.
- Look for hot keys: If a small keyspace will get heavy load, rethink shard strategy or use caching/load leveling.
- Plan for operational complexity: re-sharding, backups, replication, and monitoring cost more with sharding.
- Security and compliance: vertical partitioning can simplify isolating and auditing sensitive fields.
When answering: state the access pattern, justify the chosen partitioning, acknowledge trade-offs, and mention mitigation strategies (caching, consistent hashing, read replicas, two-phase commit alternatives, async rebalancing).
Common Pitfalls and Mitigations
- Imbalanced shards: Use better shard keys or consistent hashing; implement rebalancing tools.
- Cross-shard joins: Denormalize or maintain secondary indexes to avoid expensive joins.
- Operational overhead: Automate monitoring, routing, and resharding; use managed sharding if available.
- Data locality: Design shard keys to keep related data together when possible (e.g., by account or region).
Quick Interview Examples to Mention
- Time-series logs: shard by date ranges (range-based sharding) or roll up older data to cheaper storage (vertical cold storage).
- Multi-tenant app: shard by tenant_id to isolate tenant load and enable per-tenant scaling.
- Wide user table: vertical-split large profile blob and photos into separate tables or object storage to reduce I/O on common queries.
Final Rule of Thumb
Choose partitioning based on access patterns and growth: shard (horizontal) when rows and traffic scale out; split columns (vertical) when tables are wide and you need to read fewer bytes or isolate sensitive/hot data.
Good interview answer: explain the dominant access pattern, pick a partitioning strategy, list trade-offs, and propose concrete mitigations for common issues.
#SystemDesign #Database #SoftwareEngineering

