
Cloud Storage Gateway Interviews: Cache Hit Rate Isn’t Luck—It’s Math

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
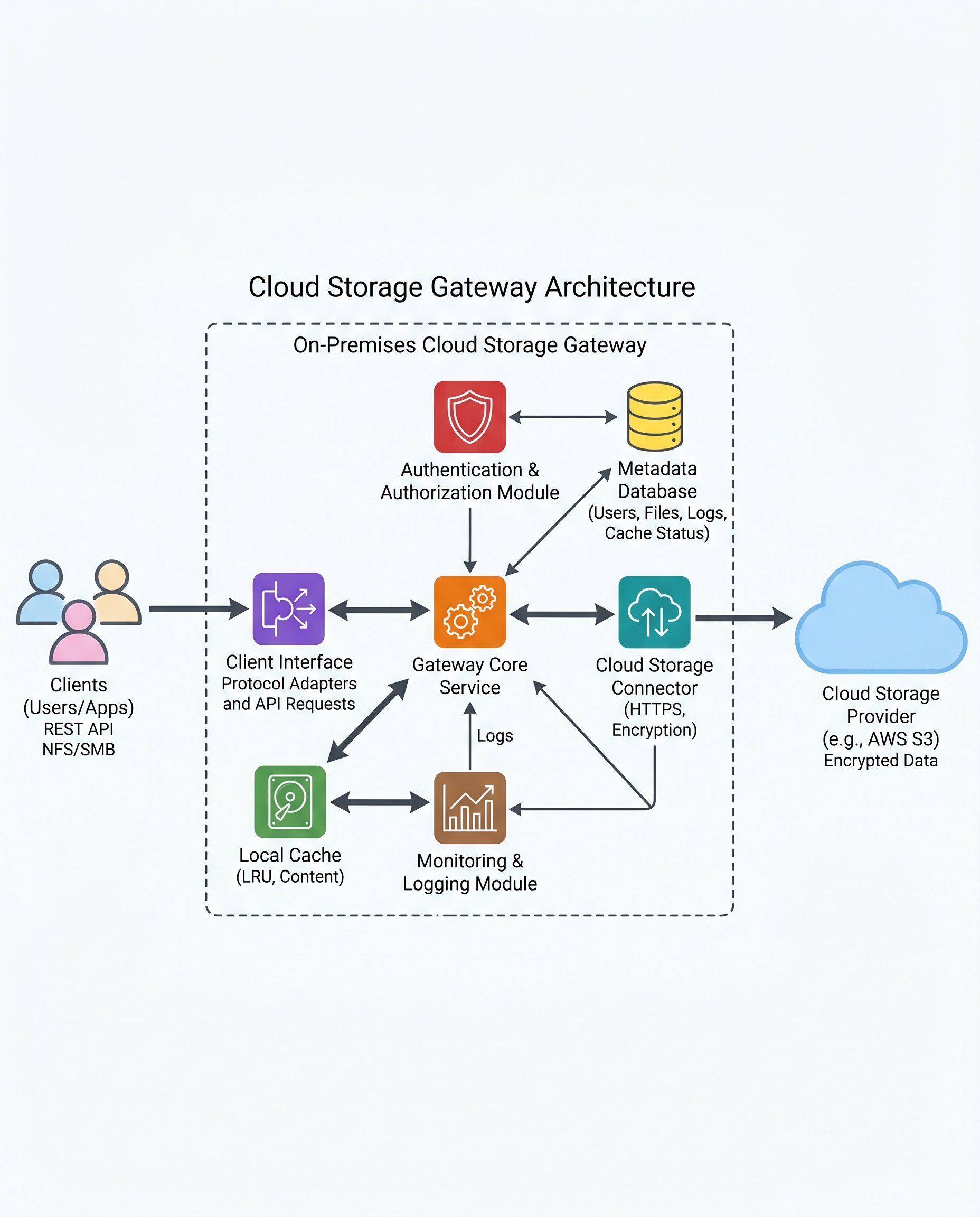
Cache hit rate isn't luck — it's predictable if you size the cache from the workload
In a Cloud Storage Gateway, local caching is your latency weapon. But don’t hand-wave cache size during design or an interview. You can estimate a practical cache size from the workload using access skew (Zipf-like behavior): a small "hot set" of objects drives most reads.
The idea in one sentence
If roughly 80% of reads come from the top 20% of files, size the cache to hold that hot set (not the entire namespace). That gives a strong hit rate for a much smaller storage footprint.
Why this works (briefly)
Most realistic workloads aren’t uniform. A small fraction of objects receives the majority of requests. This is commonly modeled with Zipf’s law (or other heavy-tailed distributions). With such skew, caching the hot set yields a large hit rate improvement for a modest cache.
Step-by-step estimation (formula + example)
Use a simple formula:
cache_size ≈ hot_set_fraction × (reads / reads_per_file) × avg_object_size
Where:
- reads = number of reads in the measurement window (e.g., per day)
- reads_per_file = average read frequency for a file that is read at least once (or invert if you measure unique files)
- hot_set_fraction = fraction of unique files that account for the majority of reads (e.g., 20% for an 80/20 rule)
- avg_object_size = average stored object size
Example from the raw notes:
- reads = 4,800 reads/day
- reads_per_file ≈ 5 reads per file → unique_files_per_day = 4,800 / 5 = 960 files
- hot_set_fraction = 20% → hot_set_size = 0.2 × 960 = 192 files
- avg_object_size = 5 MB → cache_size = 192 × 5 MB = 960 MB
Add overhead and growth margin (metadata, fragmentation, more objects, temporary bursts) → target cache ≈ 1–2 GB.
Interview checklist: justify the cache, don't guess
If asked in an interview, present the calculation and assumptions explicitly:
- State measurement window (e.g., daily reads) and source (access logs, metrics)
- Show how you derive unique files (reads ÷ reads_per_file) or compute top-K by rank
- Choose a hot_set_fraction (cite 80/20 as a start; adjust if you measure a different skew)
- Use average object size and add overhead/growth margin
- State eviction policy assumptions (LRU, LFU) and how TTLs or writes affect the effective hot set
- Provide the final recommendation (with safety margin)
Caveats & refinements
- Skew matters: if distribution is less skewed, the hot set grows and caching helps less. Measure the exponent (alpha) of your Zipf-like distribution if possible.
- Time window: the working set can change hourly/daily; choose a window that matches your SLA goals.
- Writes and consistency: write-heavy workloads and short TTLs reduce effective cache utility.
- Object size variance: if object sizes vary widely, use percentiles (median/95th) or weight by bytes when sizing.
- Eviction policy: LRU/LFU hybrid choices affect how well the hot set is retained under churn.
Quick tip on latency impact
If local cache latency is 5 ms and remote object fetch is 100 ms, improving hit rate from 0% to 80% reduces average read latency roughly by (100 - 5) × 0.8 ≈ 76 ms per read — a big win for user experience.
TL;DR (for interviews)
Don’t guess cache size. Measure the workload (reads, unique files, object size), assume a hot set (e.g., 20% for 80/20), compute the bytes to hold that set, add safety margin, and explain your assumptions. That math is your answer.

