
Churn Prediction in Interviews: The 7-Step Strategy You Must Explain Clearly

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
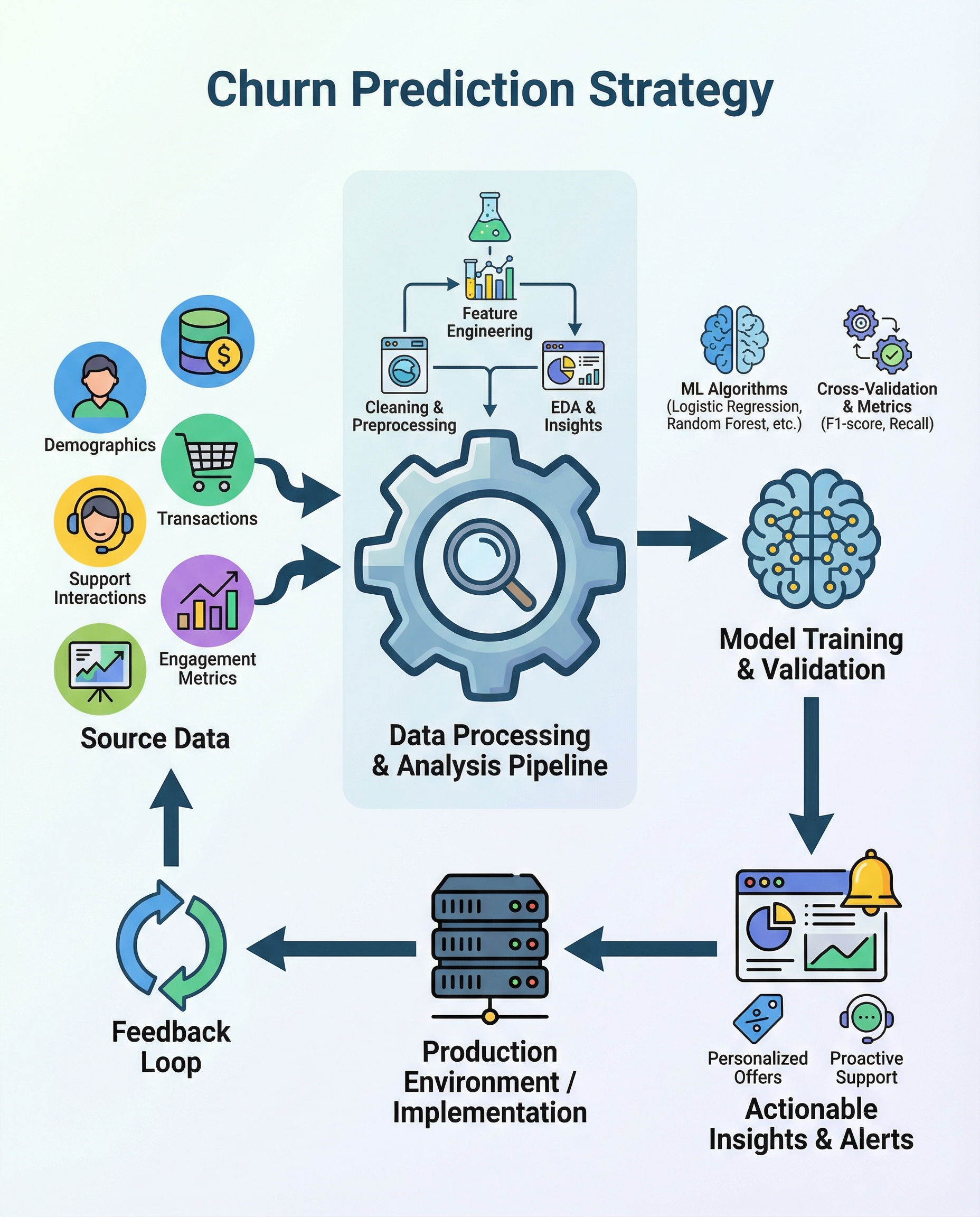
Churn Prediction in Interviews: The 7-Step Strategy You Must Explain Clearly
In interviews, churn prediction isn't just about "build a model." It's about translating business goals into a repeatable data-driven process that leads to measurable retention actions. Below is a concise, interview-ready 7-step framework you can explain clearly, plus tips, metrics, trade-offs and a short pitch you can use on the spot.
1) Define churn — and why it happens
- Clarify the business definition: churn can mean subscription cancellation, no activity for X days, downgrades, or failed renewals. Use a definition tied to downstream KPIs (MRR, LTV, retention rate).
- Identify root causes: poor product fit, low engagement, pricing/competitor moves, service issues, or onboarding friction.
- Interview tip: state the definition you’ll use and why (e.g., "I’ll define churn as 30 days of inactivity because our average churn happens after 21–45 days").
2) Collect signals (features)
- Typical signal groups:
- Demographics: age, region, company size
- Transactions: last purchase date, frequency, avg spend
- Product usage: session counts, feature usage, time spent
- Support: tickets, sentiment, response times
- Marketing: campaign exposure, email opens
- Also collect temporal/contextual features (seasonality, onboarding date).
- Interview tip: mention lagged variables and event windows (e.g., features in last 7/30/90 days).
3) Preprocess and engineer features
- Data cleaning: handle missing values, deduplicate, align time windows.
- Encoding & scaling: one-hot or target encoding for categorical vars; standardize continuous features when needed.
- Feature engineering examples: tenure, recency/frequency/monetary (RFM), rolling averages, change metrics (delta in usage), aggregation per user.
- Address class imbalance: resampling, class weights, or thresholding.
- Interview tip: explain which features capture early signals (e.g., sudden drop in key feature usage).
4) Exploratory data analysis (EDA)
- Goals: uncover drivers, segment users, verify label quality, and detect data leakage.
- Look for trends and cohorts: churn by tenure cohort, by acquisition channel, or by feature buckets.
- Use visualizations and summary stats to surface strong predictors and anomalous patterns.
- Interview tip: mention checking label leakage and temporal splits during EDA.
5) Modeling — algorithm choice & tradeoffs
- Common models: Logistic Regression (LR), Decision Trees, Random Forests, Gradient Boosted Machines (XGBoost/LightGBM/CatBoost), Neural Nets.
- Choose by tradeoff:
- Interpretability: LR, shallow trees, or explainable GBM + SHAP
- Performance: GBM/NN often win on complex patterns
- Speed/maintenance: simpler models are faster to deploy and monitor
- Metrics to optimize: precision@k, recall, F1, ROC-AUC, PR-AUC, and business metrics like activation lift or retention uplift.
- Important: frame the decision around business impact — is catching more churners (recall) worth more false positives (precision)?
6) Validate and avoid overfitting
- Proper validation: temporal train/test split, and nested cross-validation where appropriate.
- Monitor overfitting with validation curves and by comparing train vs validation metrics.
- Calibrate probabilities if you’ll use them for actioning (Platt scaling, isotonic regression).
- Assess robustness: test on cohorts, channels, and time windows.
- Interview tip: call out temporal splitting and why random CV can overestimate performance for churn.
7) Deploy, monitor, and close the feedback loop
- Integration: score users in batch or real-time and feed outputs into CRM, marketing automation, or product dashboards.
- Actions: personalized offers, targeted onboarding, customer success outreach, or in-product nudges.
- Monitor: model performance (AUC, precision@k), data drift, calibration drift, and business KPIs (retention, CLTV).
- Iterate: A/B test interventions, log outcomes, and retrain regularly with fresh labels.
- Interview tip: describe the feedback loop — predictions → action → measured outcome → model update.
Common pitfalls and how to avoid them
- Label leakage: ensure features don’t include future info that wouldn’t be available at scoring time.
- Optimizing the wrong metric: align model metrics with business objectives (e.g., maximize retained revenue, not just AUC).
- Ignoring intervention cost: consider offer cost and false positive implications.
- One-off models: build monitoring and retraining cadence to keep model healthy.
Quick interview-ready script (30–90 seconds)
"I treat churn prediction as a business process: first I define churn in a way that maps to revenue or retention goals, then collect signals like transactions, product usage and support logs. I preprocess data, engineer time-based features (tenure, recent usage deltas), and do EDA to find drivers and segments. For modeling I balance interpretability and accuracy — LR or trees when we need explainability, GBMs or NNs when accuracy matters — and I optimize for business-relevant metrics like precision@k or uplift. I validate with temporal splits to avoid leakage, deploy scores into our CRM for targeted offers, and close the loop by A/B testing interventions and retraining on results."
Final tips for interviews
- Tailor the level of technical detail to the role: product-heavy roles focus more on actions and KPIs; research roles expect discussion of algorithms and validation.
- Mention specific tools you’ve used (SQL, Python, scikit-learn, XGBoost, Airflow, Kafka) when asked.
- When asked for an example, walk through one quick case: definition → features → model → action → measured impact.
Hashtags: #DataScience #MachineLearning #TechInterviews

