
Chatbot Interviews: Stop Saying “Accuracy” — Measure Latency Like a Real Engineer

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
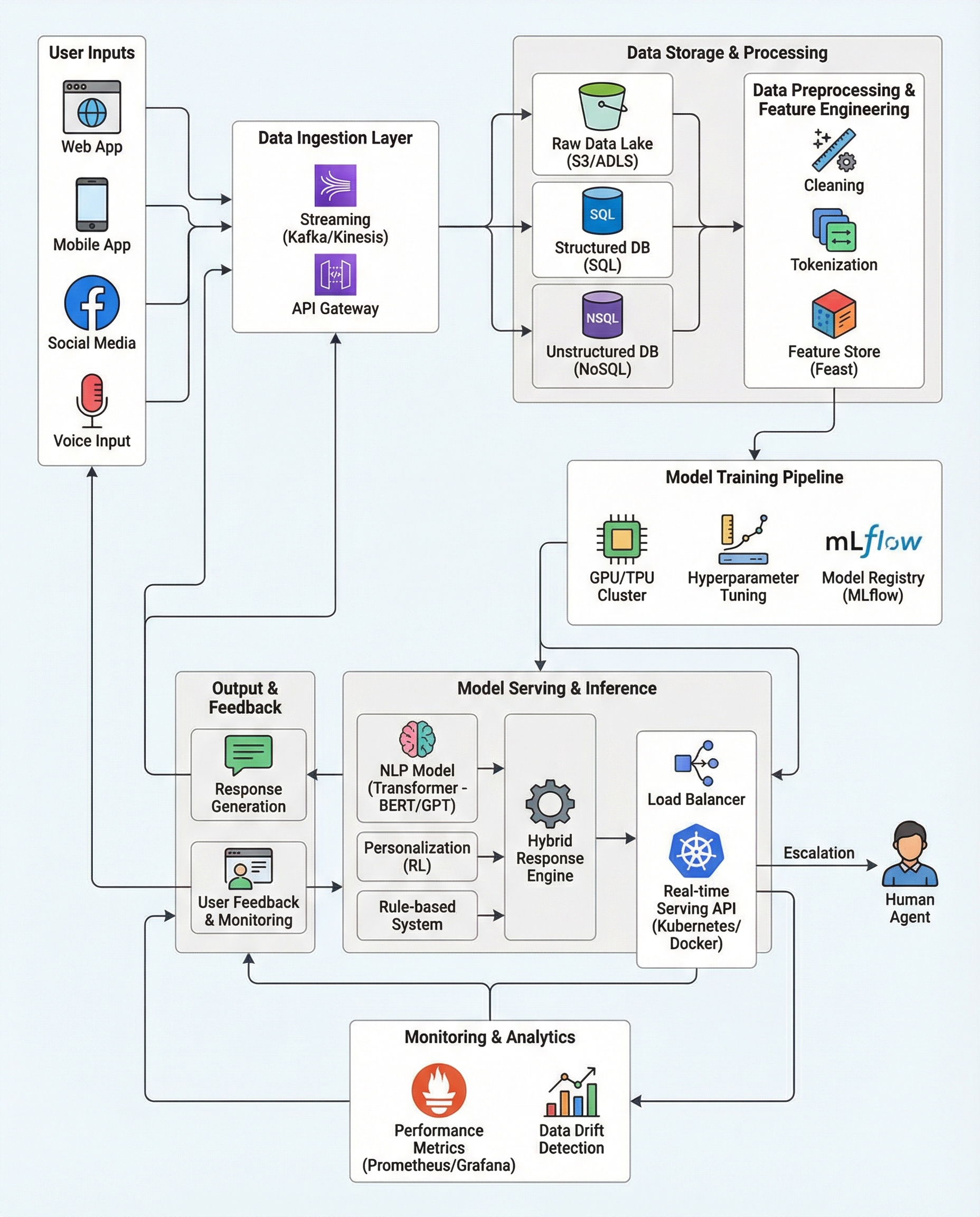
In chatbot system design, “response time < 2s” isn't a throwaway line — it's a core engineering commitment. In interviews, don't talk only about accuracy or MRR. State a clear latency budget, show how you'll measure it, and explain how you'll enforce it under load. If you can't measure p95/p99 latency, you can't credibly claim reliability.
What to say in an interview: the latency budget
Be explicit. Break latency into measurable pieces and assign a budget to each:
- Network (client ↔ server): e.g., 100–300 ms
- Retrieval / search / DB lookups: e.g., 50–300 ms
- Model inference (CPU/GPU/TPU): e.g., 300–1,500 ms
- Post-processing / reranking / formatting: e.g., 50–200 ms
Total: keep p95 under your target (for example, p95 < 2s, p99 < 4s). Say those numbers out loud. Then explain how you'll enforce them.
How to enforce the budget — concrete techniques
Give hands-on measures, tradeoffs, and monitoring plans rather than aspirational lines.
- Caching frequent intents and responses
- Cache deterministic answers and embeddings for common queries to avoid repeated retrieval or inference.
- Optimize retrieval pipeline
- Use approximate nearest neighbor (ANN) indices (FAISS, ScaNN), warm indexes, sharding, and pre-filtering to reduce retrieval time.
- Reduce model latency
- Distillation, quantization (8-bit/4-bit), pruning, and early-exit architectures can drastically cut inference time with modest quality loss.
- Smart batching & pipelining
- Batch requests on GPU where latency amortizes cost; use small, time-bounded batches for real-time flows and dynamic batch sizes.
- Streaming and partial responses
- Stream tokens to the client so perceived latency drops even if final generation continues.
- Autoscaling and capacity planning
- Horizontal autoscaling with warm pools, concurrency limits, and admission control to avoid overload.
- Graceful degradation
- Fall back to smaller models, cached replies, or simpler heuristics when budgets are at risk.
- Observability & SLOs
- Monitor p50/p95/p99 latency per component, error rates, queue lengths, and tail latencies. Create alerts for SLO breaches and throttling events.
- Load testing and chaos
- Regularly run load tests (Locust, k6) and inject failures to ensure SLOs hold under realistic traffic.
Measurement matters: report p95 and p99
- p50 (median) is useful, but tails break user experience. Always measure and report p95 and p99 for the whole request path and for components.
- Measure client-to-client latency (end-to-end) and component-level latencies (network, retrieval, inference, post-processing).
- Use distributed tracing (OpenTelemetry) and consistent timestamps to reconstruct end-to-end latency.
Tradeoffs and how to frame them
- Accuracy vs latency: present concrete options. "I can reach higher ROUGE/accuracy with the large model, or meet p95 < 2s with a distilled/quantized model plus reranking. Which do you prefer?" This shows you understand the trade space.
- Cost vs latency: show awareness of GPU/CPU cost and autoscaling strategies (spot instances vs warm on-demand, warm pools).
Interview-ready soundbites (short, precise)
- "I'd set a latency budget: network + retrieval + inference + post-processing, and target p95 < 2s, p99 < 4s."
- "We'll enforce it with caching, retrieval optimizations, model distillation/quantization, bounded batching, and autoscaling with SLO alerts."
- "We measure p95/p99 end-to-end. If we can't measure them, we can't claim reliability."
Quick checklist to show in an interview
- Defined end-to-end SLOs (p95/p99)
- Component budgets (network, retrieval, inference, post-processing)
- Concrete latency reduction techniques (caching, distillation, ANN, batching)
- Observability plan (tracing, dashboards, alerts)
- Load-testing cadence and fallback strategies
If you can’t measure p95/p99 latency and explain how you would keep it under budget, you’re not yet speaking like a systems engineer — you’re reciting hopes. Bring numbers, a plan, and the monitoring to prove it.
#MachineLearning #MLOps #SystemDesign

