
Chat System Interviews: The One Partition Key That Makes or Breaks Your Design

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
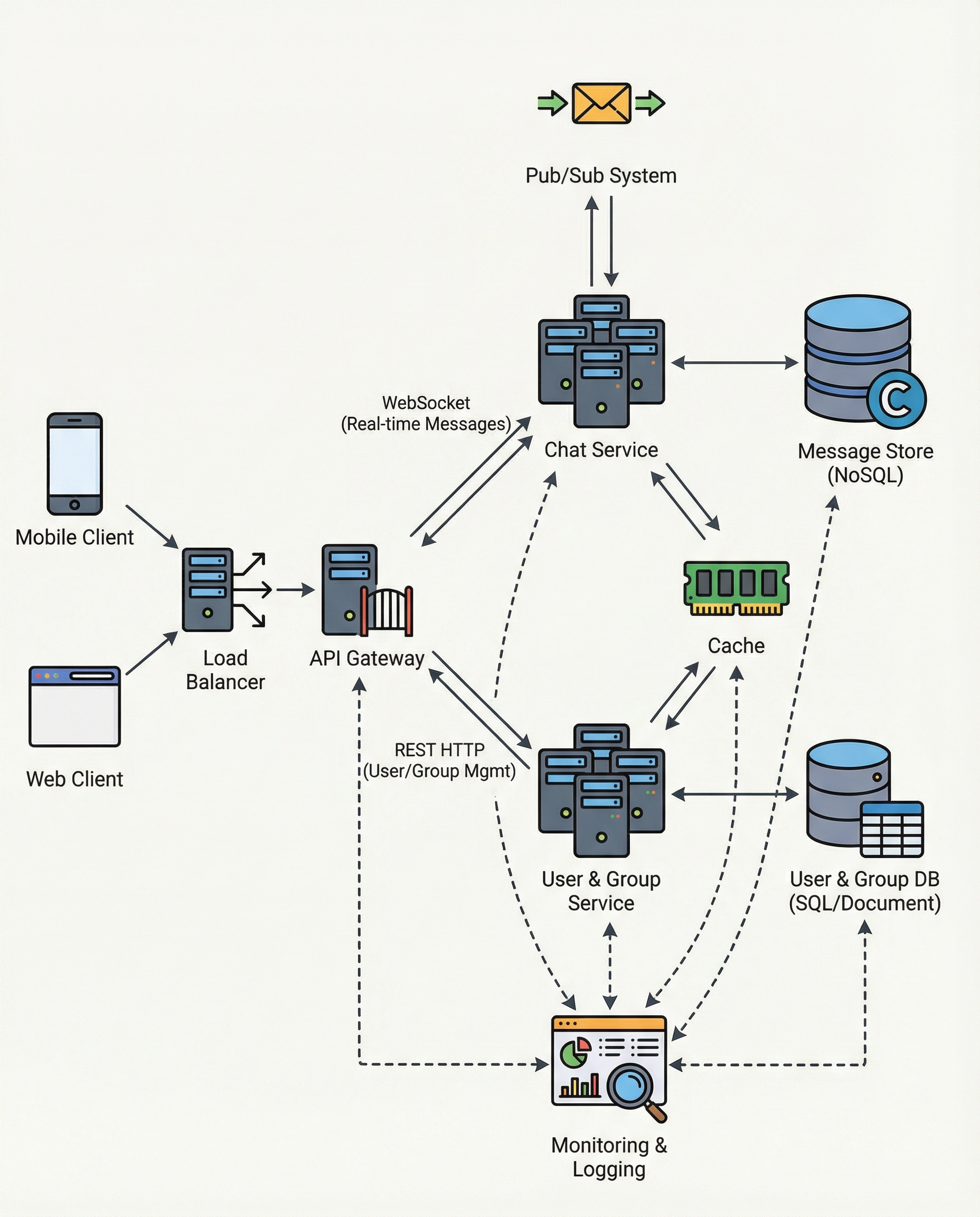
The partition key that makes or breaks your chat design
In chat systems, the way you design the message table often determines whether your service scales or collapses under load. A common and powerful pattern for NoSQL stores (e.g., Cassandra) is:
- partition key:
group_id - clustering key:
timestamp(or a time-based UUID)
This choice is simple but deliberate — it optimizes the dominant access pattern for chat: "give me the messages for this conversation, in order." Below I explain why interviewers care, show a compact schema example, and cover trade-offs and mitigation strategies you should mention in interviews.
Why interviewers care
Fast reads for the dominant query
- Chat history queries are typically: "fetch messages for this chat (group_id), ordered by time, possibly paginated." With
partition_key = group_idandclustering_key = timestamp, the DB can do a single range scan and return results quickly.
- Chat history queries are typically: "fetch messages for this chat (group_id), ordered by time, possibly paginated." With
Append-friendly writes
- Writes are essentially append-only. Because each conversation (group) is a separate partition, writes spread across many partitions and avoid single-point write bottlenecks when groups are numerous.
Natural ordering
- The clustering key provides chronological ordering out of the box, so you don't need extra sorting at read time.
Rule of thumb: optimize for your dominant access pattern rather than chasing generic flexibility.
Example (Cassandra-style) table
CREATE TABLE messages (
group_id uuid,
created_at timeuuid,
message_id uuid,
sender_id uuid,
body text,
PRIMARY KEY (group_id, created_at)
) WITH CLUSTERING ORDER BY (created_at ASC);
Notes:
- Use a time-based UUID (
timeuuid) forcreated_atwhen you need both uniqueness and time ordering. - Store message metadata (sender, attachments pointers, status) alongside or in another table depending on read patterns.
Important trade-offs and pitfalls (mention these in interviews)
Hot partitions
- If a single group receives a huge fraction of writes (e.g., a public channel), that partition becomes a hotspot. Solutions: bucket the partition (see below), offload high-volume chatter to sharded topics, or use separate storage for high-traffic channels.
Unbounded partitions
- Very large partitions hurt compaction and repair. Introduce time-bucketed partitions (e.g.,
PRIMARY KEY ((group_id, day), created_at)) or use TTLs/archival to bound partition size.
- Very large partitions hurt compaction and repair. Introduce time-bucketed partitions (e.g.,
Tombstones and deletes
- Frequent deletes create tombstones that harm read performance. Prefer TTLs or soft-delete strategies and batch deletions where possible.
Consistency and ordering across replicas
- NoSQL systems offer tunable consistency. In interviews, be ready to discuss required read/write consistency (e.g., QUORUM) and how eventual consistency affects perceived ordering.
Secondary queries
- If you need queries like "search my messages for a keyword" or "list all groups for a user sorted by last message", additional indexes or denormalized tables are required. Design those tables to match each access pattern.
Common mitigations (patterns to mention)
Bucketing (time or hash):
- Partition by (group_id, bucket) where bucket = day or a hash mod N. This keeps partitions bounded and reduces hotspots.
Materialized views / denormalization:
- Maintain a per-user inbox table to support fast retrieval of recent conversations and unread counts.
Archival pipeline:
- Move old messages to cold storage (S3) and only keep recent messages in the fast store.
TTLs and compaction tuning:
- Use TTL for ephemeral chats and tune compaction to reduce the impact of tombstones.
What to say in an interview
- State the dominant access pattern (read history per chat, chronological). Explain how partitioning by
group_idwith timestamp clustering satisfies that pattern efficiently. - Call out trade-offs (hot partitions, unbounded growth) and propose mitigations (bucketing, TTLs, archival).
- Mention how additional requirements (search, per-user views, message edits/deletes) change the schema — you will likely need denormalized tables or indices.
Quick checklist
- Is the dominant pattern "messages by chat, ordered by time"? Use partition =
group_id, clustering =timestamp. - Do you expect very large or very hot groups? Add bucketing or sharding.
- Need global search or per-user lists? Add supporting denormalized tables.
Optimizing for the dominant access pattern wins interviews and production systems. The partition key is small to state but huge in consequences.
#SystemDesign #DistributedSystems #SoftwareEngineering

