
CDN Interviews: Cache Invalidation Is Where Candidates Fail

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
CDN Interviews: Cache Invalidation Is Where Candidates Fail
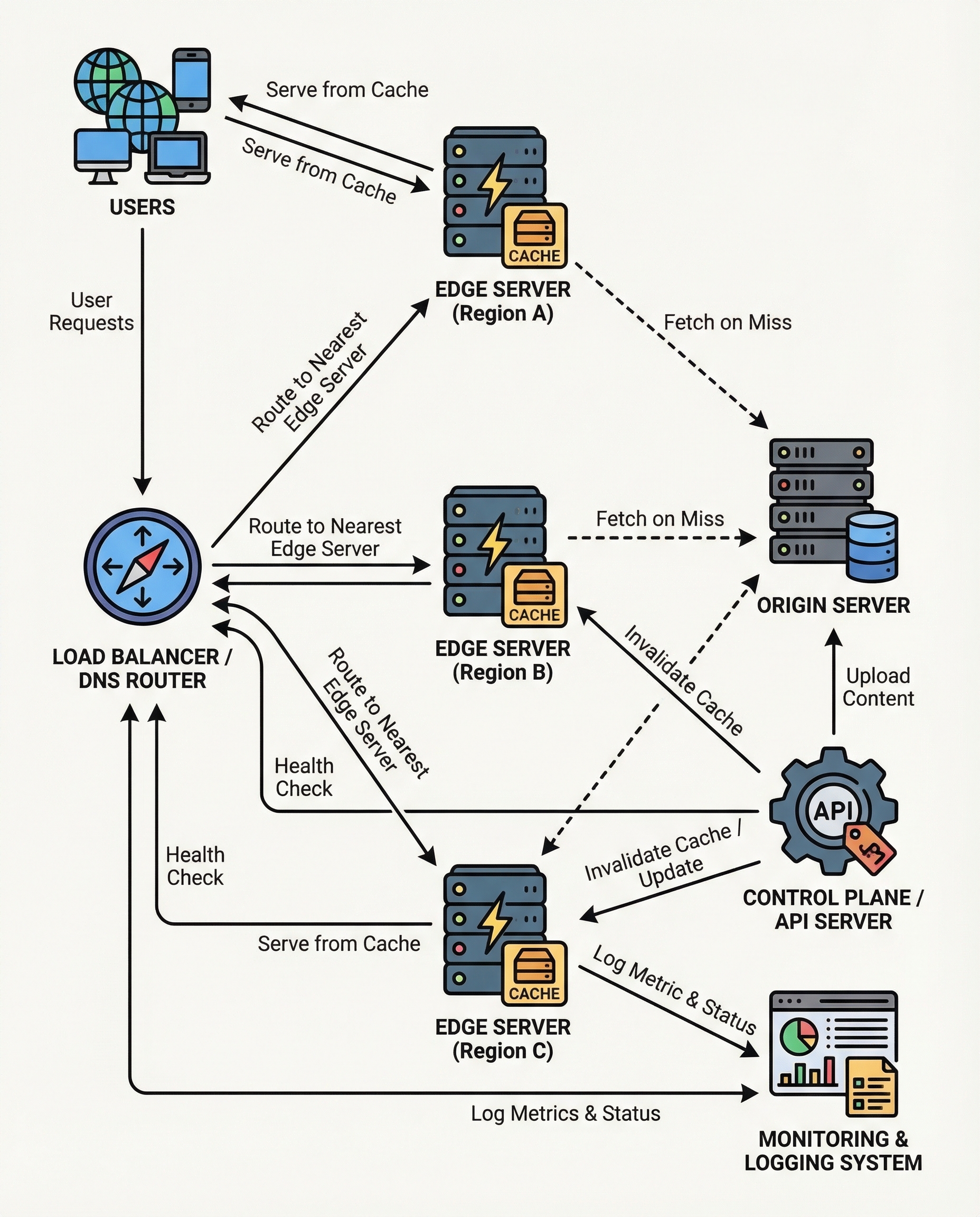
In conversation, "caching" sounds simple. In production, caching is operationally subtle. The real interview signal isn’t whether a candidate can recite HTTP headers — it’s whether they can explain how an "origin changed" event becomes "edges stop serving stale bytes."
Below I break that transformation down, compare the two common strategies you’ll see in real systems, and show the practical trade-offs and operational patterns you should know.
The core problem
When the origin (authoritative store) updates content, every CDN edge that cached the previous version must stop serving that stale copy. That requires two pieces:
- A way to detect or be told that an object changed.
- A way to make each edge evict or refresh its cached bytes (or mark them stale and revalidate on next request).
Timing matters: the sooner edges stop serving stale bytes, the fresher the content — but freshness comes at cost (lower hit rate, more origin / control traffic, greater system complexity).
Two common strategies
1) TTL-based expiry (time-to-live)
How it works
- Each object is cached at the edge with a TTL (Cache-Control: max-age or surrogate headers).
- Edges serve cached bytes until the TTL expires, then either revalidate with the origin (If-Modified-Since / ETag) or fetch a fresh copy.
Pros
- Simple and cheap to operate.
- Minimal control-plane traffic: edges make conditional requests only when TTLs expire.
- Predictable load: you can size origin load roughly from TTLs and traffic.
Cons
- Accepts bounded staleness: content is stale until TTL expiration (unless you use shorter TTLs or revalidation hacks).
- Short TTLs increase origin traffic and reduce hit ratios.
When to use
- Static assets (versioned files, immutable objects) — give very long TTLs.
- Content where slight staleness is acceptable (analytics dashboards with a few seconds/minutes lag).
Variants and enhancements
- stale-while-revalidate: serve stale content while fetching a fresh copy in the background, reducing latency while improving freshness over time.
- conditional revalidation: use ETag/If-Modified-Since to avoid transferring bytes if not changed.
2) Explicit purge / invalidation API (control-plane invalidation)
How it works
- Origin or a controlling service calls the CDN’s purge API to tell edges to evict or revalidate specific objects or patterns (by URL, content_id, or surrogate-key).
- The control plane must fan out the invalidation to every POP, handle retries, and deal with partial failures.
Pros
- Fast: you can make freshly changed content appear on edges almost immediately.
- Precise: you can target a single asset, or a key-tagged group of assets, without globally shortening TTLs.
Cons
- Operational complexity: you need a reliable control plane that fans out invalidations, tracks acknowledgements, and retries failures.
- Control traffic: invalidations themselves are additional traffic and state changes for the CDN.
- Potential for race conditions if purge semantics are not idempotent or if new content is published concurrently.
Common patterns
- Surrogate keys / content IDs: tag responses with keys so you can purge groups (e.g., all assets for a page) in one call.
- Batch invalidations and rate-limit them to avoid thrashing the CDN or overloading the control plane.
- Implement idempotent invalidation operations and stable identifiers to avoid accidental misses/duplicates.
The trade-off, clearly stated
- Stronger freshness (short TTLs, immediate purges) = lower cache hit rate + higher origin/control-plane traffic + more complexity.
- Weaker freshness (long TTLs) = higher hit rate + lower origin load but more staleness.
There’s no free lunch. Design choices depend on where you need low latency for writes, how much origin traffic you can tolerate, and how much operational complexity you can manage.
Operational implementation notes (what interviewers look for)
- Fan-out mechanism: use a robust pub/sub or control-plane queue to push invalidations to POPs. Ensure retries, exponential backoff, and dead-lettering for permanent failures.
- Idempotency and ordering: invalidation requests should be idempotent. Consider versioned keys or timestamps so older invalidations don’t accidentally override newer content.
- Metrics and SLAs: track invalidation latency (origin change → edge honor), cache hit ratio, origin request rate, and control-plane error rates.
- Safety nets: use short-lived soft TTLs combined with purge for critical updates (soft purge marks stale and forces revalidation on next request; hard purge evicts immediately).
- Testing: exercise purge paths in staging and measure time-to-visibility across POPs.
Practical recommendations (patterns by use case)
- Immutable assets (fingerprinted JS/CSS/images): very long TTL, no purge needed.
- Dynamic pages with strong freshness requirements (e.g., user-visible content changes): short TTLs + purge-by-surrogate-key for specific updates.
- High-read, low-write content with occasional updates: medium/long TTL + purge for updates.
- APIs / JSON endpoints: use conditional GETs (ETag/Last-Modified) with sensible TTLs and purge only for exceptional cases.
Quick checklist for interviews
- Explain TTL vs purge and the freshness vs hit-rate trade-off succinctly.
- Describe how to fan out invalidations (pub/sub, queues), and why retries/idempotency matter.
- Mention surrogate-keys or content IDs to avoid purging lots of URLs individually.
- Cover monitoring: invalidation latency, cache hit ratio, origin requests.
- Talk about soft vs hard purge, stale-while-revalidate, and conditional revalidation.
Closing
Candidates who can’t move from the high-level idea of "invalidate the cache" to the engineering details (fan-out, retries, idempotency, metrics, and trade-offs) usually fail the CDN question. In production, cache invalidation is where theory meets operational reality.
#SystemDesign #DistributedSystems #CloudComputing

