
Batch Sync vs Real-Time: The Interview Trade-off You Must Nail
bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
Batch Sync vs Real-Time: The Interview Trade-off You Must Nail
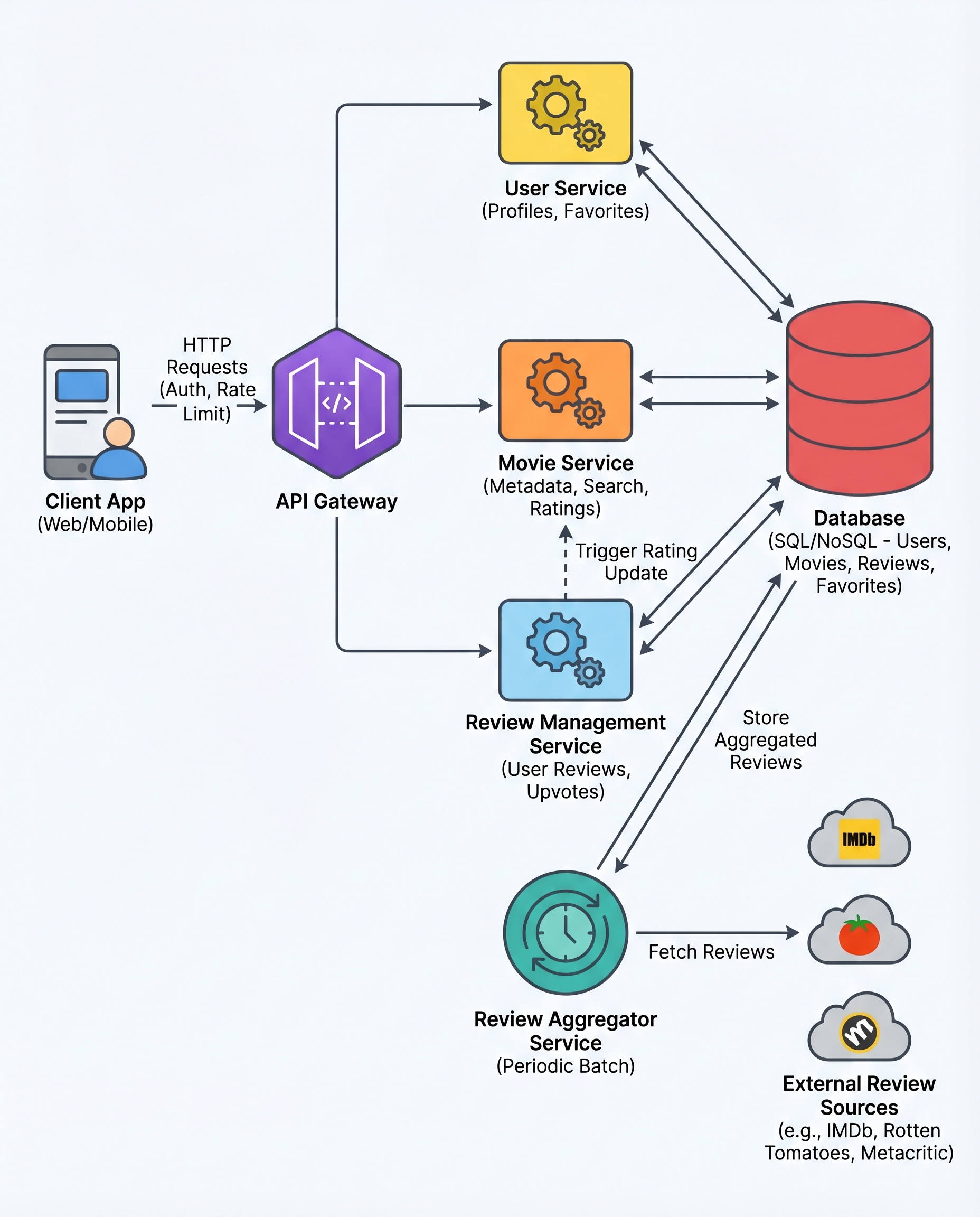
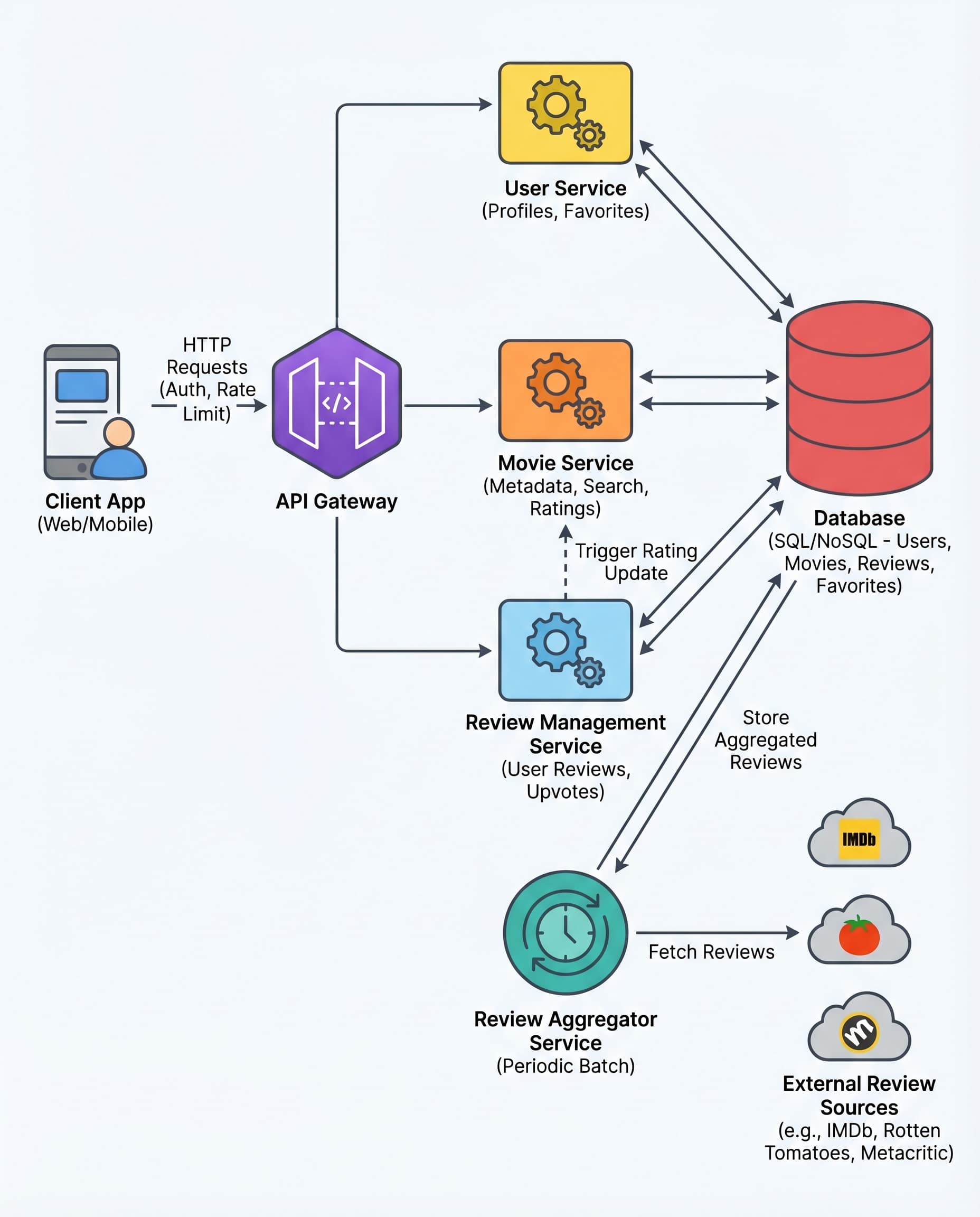
When designing a Movie Reviews Aggregator (or any system that surfaces third‑party data), there’s a simple, high‑impact rule you should adopt and be ready to state in interviews:
Reads must not depend on external services.
Here’s why that rule matters, how to implement it, and how to phrase the trade‑offs during an interview.
The problem with calling external APIs on user requests
Real‑time calls to third‑party services during user requests cause three common and painful problems:
- Latency: each remote call increases end‑to‑end response time.
- Amplified failures: flaky APIs turn into flaky user experiences.
- Rate limits: every user request burns third‑party quota and can throttle your system.
So avoid making user reads depend on external services whenever possible.
The recommended pattern: scheduled batch sync
Instead of fetching reviews during a user request, run a background pipeline on a schedule (e.g., daily, hourly, or whatever freshness your product requires). The pipeline:
- Pulls data from external services.
- Normalizes fields into your canonical schema.
- Deduplicates identical reviews and merges updates.
- Applies idempotent writes to your DB/cache.
- Retries failed calls with exponential backoff and respects rate limits.
Users read from your database or cache; the background job handles all external dependencies. This decouples user experience from flaky third‑party APIs and protects your app from cascading failures.
Implementation details & best practices
- Sync cadence: choose based on product needs (minutes for near‑real‑time, hours/days for archival). Be explicit about acceptable staleness.
- Incremental syncs: use timestamps, change tokens, or cursor-based pagination to fetch only deltas.
- Rate‑limit handling: implement token buckets, global throttling, coordinated backoff across workers, and distributed rate‑limit state where needed.
- Retries and backoff: exponential backoff + jitter, capped retries, and circuit breakers to avoid thrashing.
- Idempotency & deduplication: use stable external IDs or deterministic hashes to dedupe and make writes safe to retry.
- Normalization: map disparate fields into a unified schema and mark source metadata.
- Storage & cache: store canonical data in your DB and use a cache (Redis, CDN) for hot reads. Tune TTLs according to sync cadence.
- Observability: emit metrics for freshness, success/failure rates, error breakdowns, and remaining rate limit budgets. Alert on sync pipeline failures and freshness breaches.
User UX: surface staleness and control
Accept controlled staleness and be transparent:
- Show a “last updated” timestamp for each review set or movie page.
- Offer a limited "Refresh" or "Request latest" button that queues a background re‑sync (do not make it perform live external calls on the user request path).
- Provide clear messaging when data is stale or an external provider is degraded.
Interview phrasing and trade‑offs
When an interviewer probes this design, state the rule, explain the trade‑off, and offer alternatives:
- Clear rule: “Reads must not depend on external services; we decouple via a scheduled background sync and reads from our DB/cache.”
- Trade‑off: “We accept controlled staleness (X minutes/hours) to gain reliability, predictable latency, and protection from rate limits.”
- If challenged for real‑time: describe hybrid options — webhooks, streaming updates, or push notifications from the source, or a near‑real‑time pipeline (Kafka, change data capture) — and discuss added complexity (operational cost, delivery guarantees, rate limiting, and schema/versioning).
Common interview follow‑ups you should be ready to discuss:
- How do you pick the sync cadence? (Answer: product needs, SLAs, and rate limits.)
- How do you handle a provider outage? (Answer: circuit breakers, stale data messaging, retries with backoff, and metrics/alerts.)
- When would you choose real‑time? (Answer: only when business needs justify the complexity — e.g., trading systems, live bidding, or chat.)
Quick checklist to present in an interview
- [ ] Reads never call third‑party services synchronously.
- [ ] Background sync pipeline: pull → normalize → dedupe → store.
- [ ] Retries with exponential backoff and circuit breakers.
- [ ] Rate‑limit coordination and throttling.
- [ ] Idempotent writes and dedupe keys.
- [ ] Expose "last updated" timestamps and UX for staleness.
- [ ] Monitoring and alerts for freshness and failure rates.
- [ ] Alternatives considered: webhooks / streaming for near‑real‑time.
In short: prefer scheduled batch syncs for user reads, accept controlled staleness, and be explicit about the trade‑offs. That concise statement — backed by the above implementation details — is exactly the kind of crisp design stance interviewers want to hear.

