
The One Detail Interviewers Hunt For: Atomic “Claiming” of Jobs

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
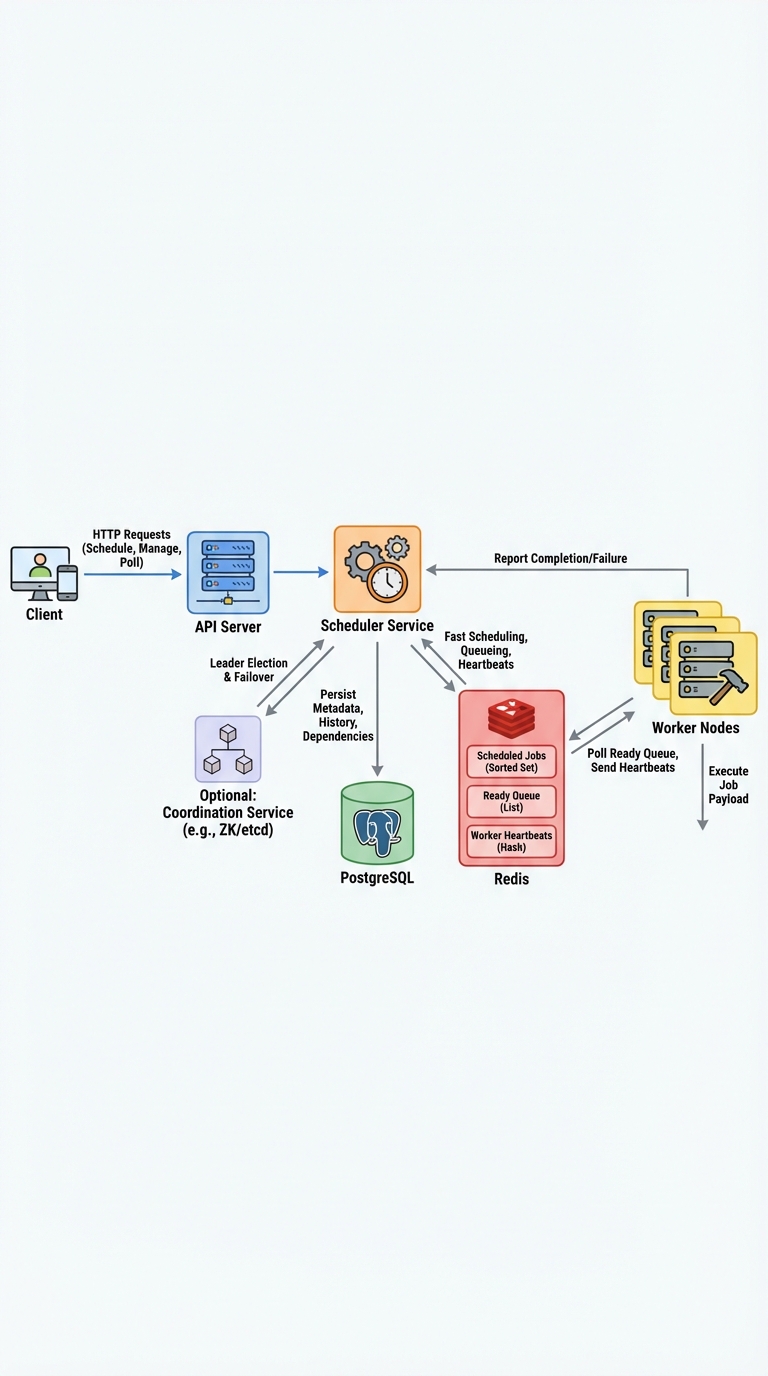
The One Detail Interviewers Hunt For: Atomic “Claiming” of Jobs
In a distributed scheduler, the biggest enemy is duplicate execution. The common instinct—add more locks—usually complicates things. The clean, reliable fix is an atomic "claim" step: move a job from a scheduled set into a ready queue with one atomic operation, then have workers claim and lease work atomically.
The problem
When multiple schedulers or workers race to run the same job, you get duplicate executions. That breaks correctness for many tasks and creates subtle bugs. We want at-least-once delivery semantics without chaos and without fighting race conditions with ad-hoc locking.
The solution: an atomic claim step
Key idea: when a job becomes due, perform a single atomic operation that removes the job from the scheduled set and places it into the ready queue. This ensures only one actor can make the job available to workers.
Example (Redis): use a Lua script to combine ZPOPMIN and LPUSH so both actions happen atomically on the Redis server:
-- KEYS[1] = scheduled_zset, KEYS[2] = ready_list
local popped = redis.call('ZPOPMIN', KEYS[1])
if popped and popped[1] then
local job = popped[1]
redis.call('LPUSH', KEYS[2], job)
return job
end
return nil
After the scheduler has atomically moved the job into the ready queue, workers must fetch and claim it safely.
Worker behavior (claim + lease)
- Worker atomically pops a job from the ready queue (e.g.,
BLPOP) to get exclusive ownership of the work item. - Immediately record a short-lived lease for the job:
SET job:<id>:lease <worker-id> PX <lease-ms> NX. This marks the worker as the owner for the lease duration. - Run the job and periodically extend the lease (heartbeat) while the job is still running.
- On success, remove the job and delete the lease. On failure, either requeue manually or let the lease expire and let the scheduler requeue.
If a worker dies or loses connectivity, its lease will expire. The scheduler or a reaper process should detect expired leases and requeue those jobs back into the ready queue (or scheduled set) so other workers can pick them up.
Why this works for at-least-once delivery
- The atomic move prevents multiple schedulers from exposing the same job to workers.
- The worker-side atomic pop prevents multiple workers from working the same job simultaneously.
- Leases/heartbeats allow safe reclamation: if a worker dies, the job becomes available again after lease expiry.
This yields at-least-once semantics: a job might run more than once (if the original worker failed after doing partial work), so aim for idempotent job handlers.
Practical tips & pitfalls
- Lease duration: pick slightly longer than your expected heartbeat interval but short enough to allow quick recovery on failure.
- Heartbeats: refresh leases frequently while the job runs to avoid false reclaims for long tasks.
- Idempotency: design handlers to be safe to run multiple times (dedupe by job id, check completed markers, use transactional side-effects).
- Centralized atomicity: use the same Redis instance for both the scheduled set and the ready queue so server-side atomic operations (Lua) are reliable.
- Network partitions & partial failures: a worker could complete a job but fail before deleting the lease; the job may be retried—hence idempotency matters.
- Monitoring: surface metrics for leases, requeues, and stuck jobs so you can tune lease length and detect bad patterns.
- Alternatives: managed queues like SQS use a visibility timeout pattern (similar concept). The core idea—atomic claim + lease—is the same.
Summary
Don't fight races with ad-hoc locks. Implement an atomic claiming step (move scheduled -> ready atomically), have workers pop and record a lease, and requeue after lease expiry. This pattern keeps duplicate execution under control while enabling safe at-least-once delivery.
#SystemDesign #DistributedSystems #SoftwareEngineering

