
80K Events/sec? The One Design Move That Saves Your Health Monitoring System

bugfree.ai is an advanced AI-powered platform designed to help software engineers master system design and behavioral interviews. Whether you’re preparing for your first interview or aiming to elevate your skills, bugfree.ai provides a robust toolkit tailored to your needs. Key Features:
150+ system design questions: Master challenges across all difficulty levels and problem types, including 30+ object-oriented design and 20+ machine learning design problems. Targeted practice: Sharpen your skills with focused exercises tailored to real-world interview scenarios. In-depth feedback: Get instant, detailed evaluations to refine your approach and level up your solutions. Expert guidance: Dive deep into walkthroughs of all system design solutions like design Twitter, TinyURL, and task schedulers. Learning materials: Access comprehensive guides, cheat sheets, and tutorials to deepen your understanding of system design concepts, from beginner to advanced. AI-powered mock interview: Practice in a realistic interview setting with AI-driven feedback to identify your strengths and areas for improvement.
bugfree.ai goes beyond traditional interview prep tools by combining a vast question library, detailed feedback, and interactive AI simulations. It’s the perfect platform to build confidence, hone your skills, and stand out in today’s competitive job market. Suitable for:
New graduates looking to crack their first system design interview. Experienced engineers seeking advanced practice and fine-tuning of skills. Career changers transitioning into technical roles with a need for structured learning and preparation.
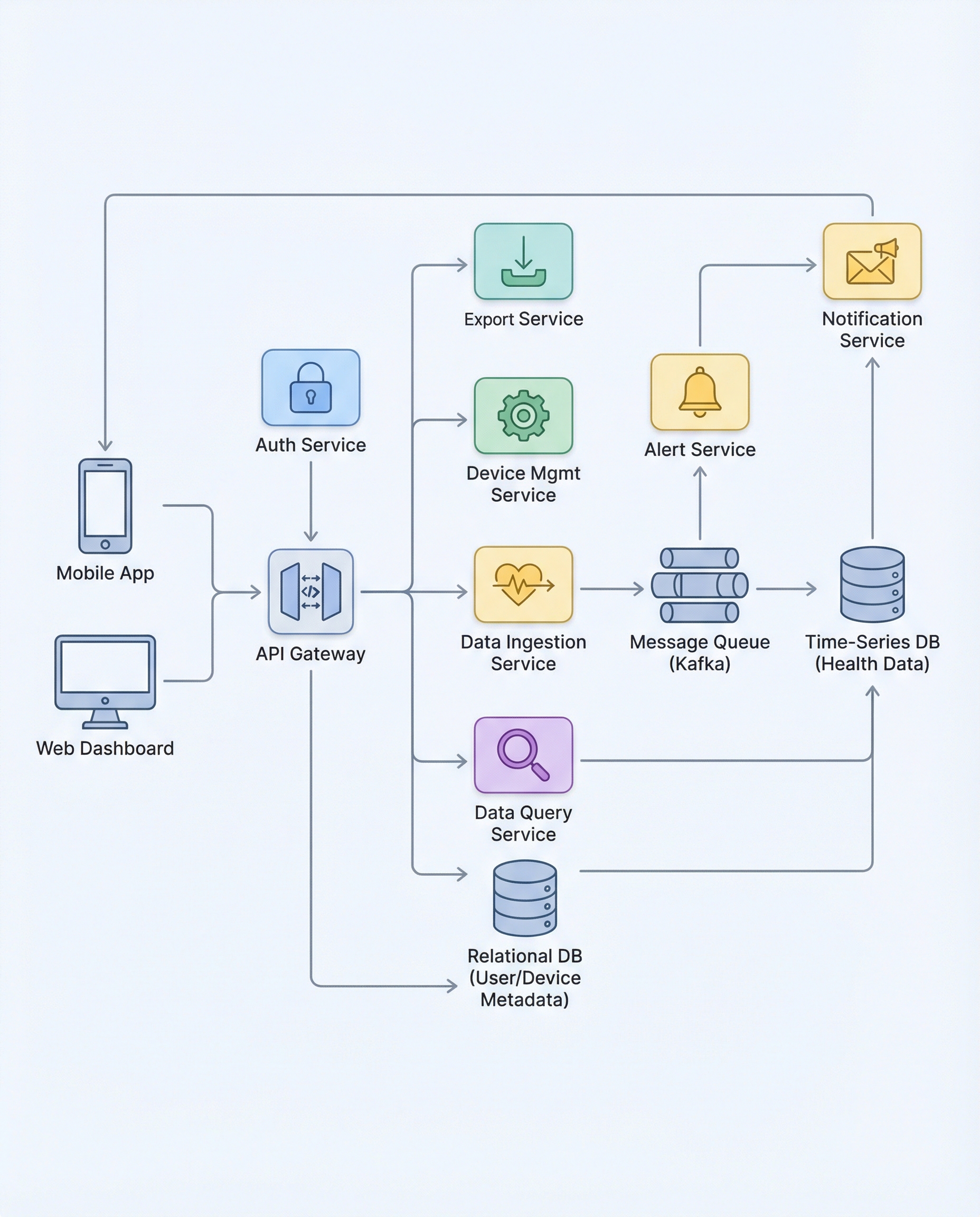
80K Events/sec? The One Design Move That Saves Your Health Monitoring System
If your health monitoring pipeline ever sees spikes — think ~80,000 data points/sec — writing directly to the database becomes the weakest link. A brief DB slowdown or spike during ingestion will drop data, delay alerts, or crash upstream services.
The right, simple design move: decouple ingestion from storage and processing with a message queue (Kafka, Google Pub/Sub, etc.). In this pattern the ingestion service only validates and enqueues events; downstream consumers persist to the time-series DB and run alert rules. This separation buys you buffering, backpressure, retries, and independent scaling of writers and alerting logic.
The problem in one line
Direct-to-DB ingestion couples peak write load with DB availability. Spikes = lost points, missed alerts, and operational fire drills.
Queue-first architecture (high level)
- Ingest endpoint: lightweight service that validates, enriches minimally (timestamps, IDs), and publishes events to a queue.
- Message queue: durable buffer (Kafka / PubSub) that absorbs spikes and preserves ordering/partitioning semantics.
- Consumers: pull, batch, and persist events into your time-series DB; run alert rules as needed or forward enriched events to an alerting pipeline.
This is the diagram shown above — enqueue first, then store and process.
Why this works (benefits)
- Buffering: queue holds bursts so the DB only sees an evened-out sustained throughput.
- Backpressure: if consumers lag, producers can be slowed or shed gracefully (and you can monitor queue lag).
- Retries and durability: at-least-once delivery and dead-letter queues let you recover from transient DB failures.
- Independent scaling: scale ingestion, queue brokers, and DB writers separately based on their real bottlenecks.
- Operational isolation: alerting logic can be developed and deployed without touching the ingestion path.
Practical implementation tips
- Keep the ingestion service tiny: validate schema, attach metadata (ingest timestamp, source ID), and publish. No heavy transformation.
- Choose a partition key carefully (device ID, tenant ID) to preserve ordering for a device while distributing load.
- Use batching on consumers: write in bulk to the time-series DB to reduce per-write overhead.
- Make DB writes idempotent (upserts with a unique event ID) or design dedupe logic — queues + retries cause duplicates.
- Implement a dead-letter queue (DLQ) for events that fail persistent processing after N retries and monitor it.
- Monitor consumer lag, queue backlog, DB write latency, and error rates. Alert on growing backlog before it becomes a problem.
- Think about retention: queues are buffers, not long-term stores. Set retention based on your SLA for recovery.
- Consider exactly-once vs at-least-once semantics. In most monitoring systems at-least-once + idempotency is simpler and sufficient.
Time-series DB considerations
- Optimize for high write throughput: use bulk writes, compression, and appropriate partitioning (time + tenant/device).
- Examples: TimescaleDB, InfluxDB, ClickHouse, or a managed TSDB. Choose one that matches your write patterns and query needs.
- If alert rules are heavy, separate alert evaluation into a stream-processing layer (Kafka Streams / Dataflow / Flink) or dedicated consumer(s) so long-running rules don’t block persistence.
What to say in interviews (concise answer)
"Queue first, then store/process." Then expand with: "The ingestion service validates and enqueues events; consumers persist to the time-series DB and run alerts. This provides buffering, backpressure, retries, and independent scaling, avoiding data loss during spikes."
You can follow with succinct implementation bullets: partitioning key, batching consumers, idempotent writes, DLQ, and monitoring consumer lag.
Quick checklist before you ship
- [ ] Ingest service is stateless and minimal
- [ ] Messages are partitioned for parallelism and ordering
- [ ] Consumers batch and write idempotently to the TSDB
- [ ] Dead-letter queue and retry policy in place
- [ ] Monitoring for queue lag, DB latency, and error rates
- [ ] Capacity tested to expected peak (and beyond)
Conclusion
At ~80k events/sec, the difference between losing data and staying resilient is often one architectural decision: put a durable, partitioned queue between producers and your time-series DB. It’s a small change with outsized operational benefits.
#SystemDesign #DataEngineering #Kafka

